
So, it has been a while since my last blog. But I have been working a lot from my home office lately due to Covid. With the work, and the distractions from home, it has been a challenge to write a blog. But here it is, my new blog “Metadata driven run management”.
For my current client I developed a run management system. The scope was small, and in the next few months it will grow to carry the entire architecture. The nightly loads are made off many different steps and processes. We have chosen to begin in the middle where there was a process that caches views sequential with stored procedures. If a view should be cached or not, is managed in a separate table. Then synonyms are created to either the table(when cached) or the view.
For this I made a run management system. A combination of SSIS packages and T-SQL. The views are cached, if needed, and synonyms are being created, all in parallel. Also, load orders, batch numbers, dependencies in views are automatically set. New views are automatically added to the system and sorted, deleted views are automatically archived.
I began, by designing and implementing the model where I will store all of the metadata.

- Schema
- In the database where the views are stored and where the tables will be cached, the views are developed in different schema’s. In this table I have stored the schema’s with a sorting number. This because the schema’s needed to be loaded in a specific order.
- CachingObjects
- In this table there is a list of all the views. In this table you can set many different settings, like if a view should be cached or not, load order, batch numbering, table name(if cached) etc.
- Relation_CachingObjects_CachingObjects
- This table holds the relations between the objects in parent/child. With this I can determine load orders etc.
- Run
- This table holds all of the “Runs” that have taken place. With this system a “run” is created. The objects that will be handled in this “run” are placed in the corresponding table “RunCaching”. By doing it this way, we can create different type of runs where we can control what will be loaded or not.
- RunCaching
- A combination of RunID and CachingObjectID with some status fields.
So, there you have it. That is the model so far. The next step is to add all of the different type of loads from the night batch. So the model will expand. For this blog I have used the Pokemon card collection from my son to demo certain bits. I will not show every table, function or procedure. But below a small hint of how a run will look like in some tables:
Table: Run (ID = 6)

Table: RunCaching (ID = 6)

Table: CachingObjects

Through different views, functions and stored procedures, all of the above tables are dynamically filled. You can adjust the batch and load order settings if you want. I made a Reorder bit field in case you want to intervene manually.
Every start of a run, new objects are added to the table CachingObjects and all of the metadata is being set. For the framework mechanism I use SSIS, where everything is metadata driven. All of the logic takes place on the database and not in the SSIS package. To give you a expression of how one of the packages looks like, below is the package where the views are being cached in parallel. The packages are created with BIML and for now I have chosen for 4 batches.

And now, when I start the process by loading all of the objects with a default run it will make synonyms of these views:

And that looks like:

All of the synonyms references to views, except for one. In the metadata I have set the cache setting to true. So there is one table:

And the definition of the synonym:

I have also created a small PowerBI report which gives me the results and logging of the process.

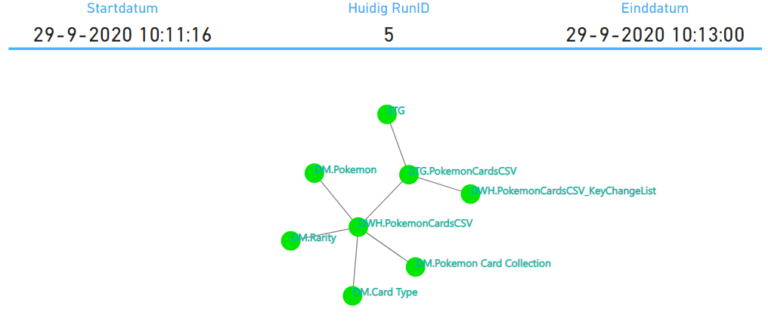
This is just a small example, but you can image how this can grow. The client for which I’m working now is a good example of how things can grow through time. Have a look at the image below. Another advantage of this, is that we can finally see all of the dependencies in one view, also the ones that should not be there.

That is it! I’m sure that I have forgotten something, but that is all for now. I haven’t shown you all of the code that actually does the magic. Like refreshing the synonyms, or caching the views, or all of the things that needs to be done for metadata logging or even the code that determines the dependencies in the views and fills the relationship table etc. If you’re interested in the code, please let me know by contacting me. Or maybe I will write another blog if people are interested enough.
Hey Frank,
Great to read your posts!
Why not choose a graph db for this solution?
Gr. Gerben
Hej Gerben!
Because that isn’t an option at the moment for my client. Besides the focus was the mechanism/framework for the entire ETL. I just started with the caching of objects. The visualization in PowerBI is actually metadata, The orbs are green because they have run successfully. If they should fail, they will be red, of the parent had failed, there orange and won’t be started in the process.
Frank
Hey Frank, great post !
Visualising the immense cluster of ETL processes always helps in understanding the impact of even the smallest change.
Great rean Frank,